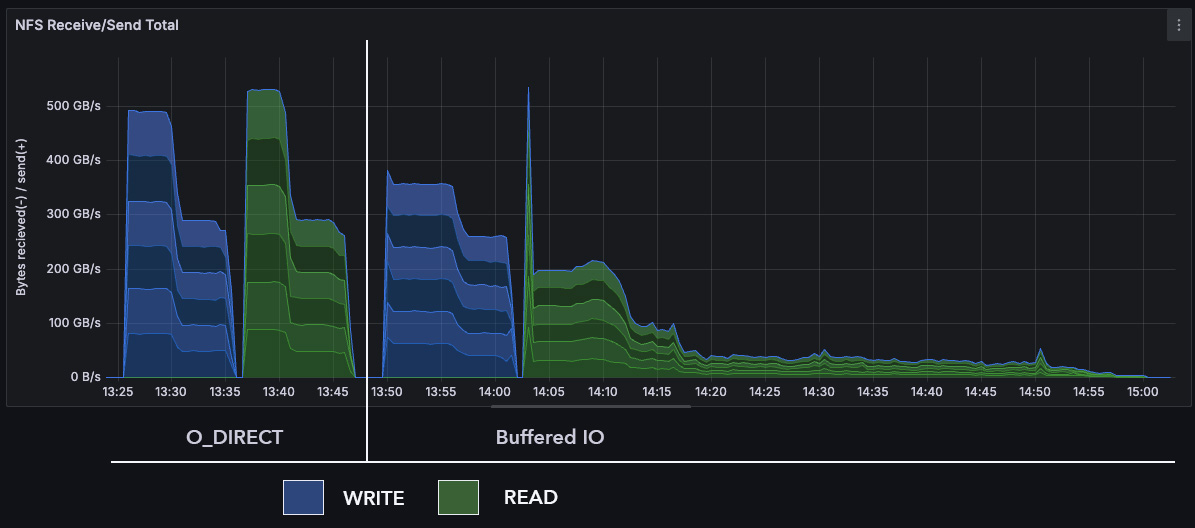
On 7/15/25 10:50 AM, Mike Snitzer wrote: > On Tue, Jul 15, 2025 at 09:59:05AM -0400, Chuck Lever wrote: >> Hi Mike, >> >> There are a lot of speculative claims here. I would prefer that the >> motivation for this work focus on the workload that is actually >> suffering from the added layer of cache, rather than making some >> claim that "hey, this change is good for all taxpayers!" ;-) > > Really not sure what you're referring to. I didn't make any > speculative claims... > >> On 7/14/25 6:42 PM, Mike Snitzer wrote: >>> Hi, >>> >>> Summary (by Jeff Layton [0]): >>> "The basic problem is that the pagecache is pretty useless for >>> satisfying READs from nfsd. >> >> A bold claim like this needs to be backed up with careful benchmark >> results. >> >> But really, the actual problem that you are trying to address is that, >> for /your/ workloads, the server's page cache is not useful and can be >> counter productive when the server's working set is larger than its RAM. >> >> So, I would replace this sentence. > > Oh, you are referring to Jeff's previous summary. Noted! ;) > >>> Most NFS workloads don't involve I/O to >>> the same files from multiple clients. The client ends up having most >>> of the data in its cache already and only very rarely do we need to >>> revisit the data on the server. >> >> Maybe it would be better to say: >> >> "Common NFS workloads do not involve shared files, and client working >> sets can comfortably fit in each client's page cache." >> >> And then add a description of the workload you are trying to optimize. > > Sure, certainly can/will do for v4 (if/when v4 needed). > >>> At the same time, it's really easy to overwhelm the storage with >>> pagecache writeback with modern memory sizes. >> >> Again, perhaps this isn't quite accurate? The problem is not only the >> server's memory size; it's that the server doesn't start writeback soon >> enough, writes back without parallelism, and does not handle thrashing >> very well. This is very likely due to the traditional Linux design >> that makes writeback lazy (in the computer science sense of "lazy"), >> assuming that if the working set does not fit in memory, then you should >> simply purchase more RAM. >> >> >>> Having nfsd bypass the >>> pagecache altogether is potentially a huge performance win, if it can >>> be made to work safely." >> >> Then finally, "Therefore, we provide the option to make I/O avoid the >> NFS server's page cache, as an experiment." Which I hope is somewhat >> less alarming to folks who still rely on the server's page cache. > > I can tighten it up respecting/including your feedback. 0th patch > header aside, are you wanting this included somewhere in Documentation? Nothing in a fixed Documentation file, at least until we start nailing down the new per-export administrative interfaces. > (if it were to be part of Documentation you'd then be welcome to > refine it as you see needed, but I can take a stab at laying down a > starting point) You are in full control of the cover letter, of course. I wanted to point out where I thought the purpose of this work might differ a little from what is advertised in this cover letter, which is currently the only record of the rationale for the series. >>> The performance win associated with using NFSD DIRECT was previously >>> summarized here: >>> https://lore.kernel.org/linux-nfs/aEslwqa9iMeZjjlV@xxxxxxxxxx/ >>> This picture offers a nice summary of performance gains: >>> https://original.art/NFSD_direct_vs_buffered_IO.jpg >>> >>> This v3 series was developed ontop of Chuck's nfsd_testing which has 2 >>> patches that saw fh_getattr() moved, etc (v2 of this series included >>> those patches but since they got review during v2 and Chuck already >>> has them staged in nfsd-testing I didn't think it made sense to keep >>> them included in this v3). >>> >>> Changes since v2 include: >>> - explored suggestion to use string based interface (e.g. "direct" >>> instead of 3) but debugfs seems to only supports numeric values. >>> - shifted numeric values for debugfs interface from 0-2 to 1-3 and >>> made 0 UNSPECIFIED (which is the default) >>> - if user specifies io_cache_read or io_cache_write mode other than 1, >>> 2 or 3 (via debugfs) they will get an error message >>> - pass a data structure to nfsd_analyze_read_dio rather than so many >>> in/out params >>> - improved comments as requested (e.g. "Must remove first >>> start_extra_page from rqstp->rq_bvec" was reworked) >>> - use memmove instead of opencoded shift in >>> nfsd_complete_misaligned_read_dio >>> - dropped the still very important "lib/iov_iter: remove piecewise >>> bvec length checking in iov_iter_aligned_bvec" patch because it >>> needs to be handled separately. >>> - various other changes to improve code >>> >>> Thanks, >>> Mike >>> >>> [0]: https://lore.kernel.org/linux-nfs/b1accdad470f19614f9d3865bb3a4c69958e5800.camel@xxxxxxxxxx/ >>> >>> Mike Snitzer (5): >>> NFSD: filecache: add STATX_DIOALIGN and STATX_DIO_READ_ALIGN support >>> NFSD: pass nfsd_file to nfsd_iter_read() >>> NFSD: add io_cache_read controls to debugfs interface >>> NFSD: add io_cache_write controls to debugfs interface >>> NFSD: issue READs using O_DIRECT even if IO is misaligned >>> >>> fs/nfsd/debugfs.c | 102 +++++++++++++++++++ >>> fs/nfsd/filecache.c | 32 ++++++ >>> fs/nfsd/filecache.h | 4 + >>> fs/nfsd/nfs4xdr.c | 8 +- >>> fs/nfsd/nfsd.h | 10 ++ >>> fs/nfsd/nfsfh.c | 4 + >>> fs/nfsd/trace.h | 37 +++++++ >>> fs/nfsd/vfs.c | 197 ++++++++++++++++++++++++++++++++++--- >>> fs/nfsd/vfs.h | 2 +- >>> include/linux/sunrpc/svc.h | 5 +- >>> 10 files changed, 383 insertions(+), 18 deletions(-) >>> >> >> The series is beginning to look clean to me, and we have introduced >> several simple but effective clean-ups along the way. > > Thanks. > >> My only concern is that we're making the read path more complex rather >> than less. (This isn't a new concern; I have wanted to make reads >> simpler by, say, removing splice support, for quite a while, as you >> know). I'm hoping that, once the experiment has "concluded", we find >> ways of simplifying the code and the administrative interface. (That >> is not an objection. call it a Future Work comment). > > Yeah, READ path does get more complex but less so than before my > having factored code out to a couple methods... open to any cleanup > suggestions to run with as "Future Work". I think the pivot from > debugfs to per-export controls will be perfect opportunity to polish. > >> Also, a remaining open question is how we want to deal with READ_PLUS >> and holes. > > Hmm, not familiar with this.. I'll have a look. But if you have > anything further on this point please share. Currently I don't think we need to deal with it in this patch set. But note that NFSv4.2 READ_PLUS can return a map of unallocated areas in a file. We should think a little about whether additional logic is needed when using O_DIRECT READs. -- Chuck Lever
{kind=link}
