On Thu, Jun 12, 2025 at 09:46:12AM -0400, Chuck Lever wrote:
> On 6/10/25 4:57 PM, Mike Snitzer wrote:
> > The O_DIRECT performance win is pretty fantastic thanks to reduced CPU
> > and memory use, particularly for workloads with a working set that far
> > exceeds the available memory of a given server. This patchset's
> > changes (though patch 5, patch 6 wasn't written until after
> > benchmarking performed) enabled Hammerspace to improve its IO500.org
> > benchmark result (as submitted for this week's ISC 2025 in Hamburg,
> > Germany) by 25%.
> >
> > That 25% improvement on IO500 is owed to NFS servers seeing:
> > - reduced CPU usage from 100% to ~50%
Apples: 10 servers, 10 clients, 64 PPN (Processes Per Node):
> > O_DIRECT:
> > write: 51% idle, 25% system, 14% IO wait, 2% IRQ
> > read: 55% idle, 9% system, 32.5% IO wait, 1.5% IRQ
Oranges: 6 servers, 6 clients, 128 PPN:
> > buffered:
> > write: 17.8% idle, 67.5% system, 8% IO wait, 2% IRQ
> > read: 3.29% idle, 94.2% system, 2.5% IO wait, 1% IRQ
>
> The IO wait and IRQ numbers for the buffered results appear to be
> significantly better than for O_DIRECT. Can you help us understand
> that? Is device utilization better or worse with O_DIRECT?
It was a post-mortum data analysis fail: when I worked with others
(Jon and Keith, cc'd) to collect performance data for use in my 0th
header (above) we didn't have buffered IO performance data from the
full IO500-scale benchmark (10 servers, 10 clients). I missed that
the above married apples and oranges until you noticed something
off...
Sorry about that. We don't currently have the full 10 nodes
available, so Keith re-ran IOR "easy" testing with 6 nodes to collect
new data.
NOTE his run was with much larger PPN (128 instead of 64) coupled with
reduction of both the number of client and server nodes (from 10 to 6)
used.
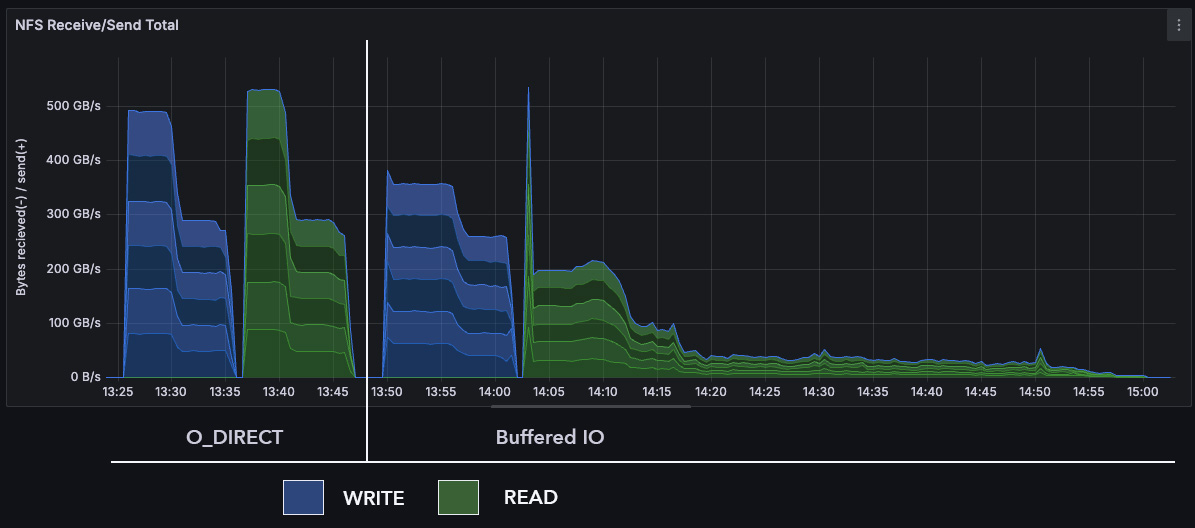
Here is CPU usage for one of the server nodes while running IOR "easy"
with 128 PPN on each of 6 clients, against 6 servers:
- reduced CPU usage from 100% to ~56% for read and 71.6% for Write
O_DIRECT:
write: 28.4% idle, 50% system, 13% IO wait, 2% IRQ
read: 44% idle, 11% system, 39% IO wait, 1.8% IRQ
buffered:
write: 17% idle, 68.4% system, 8.5% IO wait, 2% IRQ
read: 3.51% idle, 94.5% system, 0% IO wait, 0.6% IRQ
And associated NVMe performance:
- increased NVMe throughtput when comparing O_DIRECT vs buffered:
O_DIRECT: 10.5 GB/s for writes, 11.6 GB/s for reads
buffered: 7.75-8 GB/s for writes, 4 GB/s before tip over but 800MB/s after for reads
("tipover" is when reclaim starts to dominate due to inability to
efficiently find free pages so kswapd and kcompactd burn a lot of
resources).
And again here is the associated 6 node IOR easy NVMe performance in
graph form: https://original.art/NFSD_direct_vs_buffered_IO.jpg
> > - reduced memory usage from just under 100% (987GiB for reads, 978GiB
> > for writes) to only ~244 MB for cache+buffer use (for both reads and
> > writes).
> > - buffered would tip-over due to kswapd and kcompactd struggling to
> > find free memory during reclaim.
This memory usage data is still the case with the 6 server testbed.
> > - increased NVMe throughtput when comparing O_DIRECT vs buffered:
> > O_DIRECT: 8-10 GB/s for writes, 9-11.8 GB/s for reads
> > buffered: 8 GB/s for writes, 4-5 GB/s for reads
And again, here is the end result for the IOR easy benchmark:
{kind=link}
