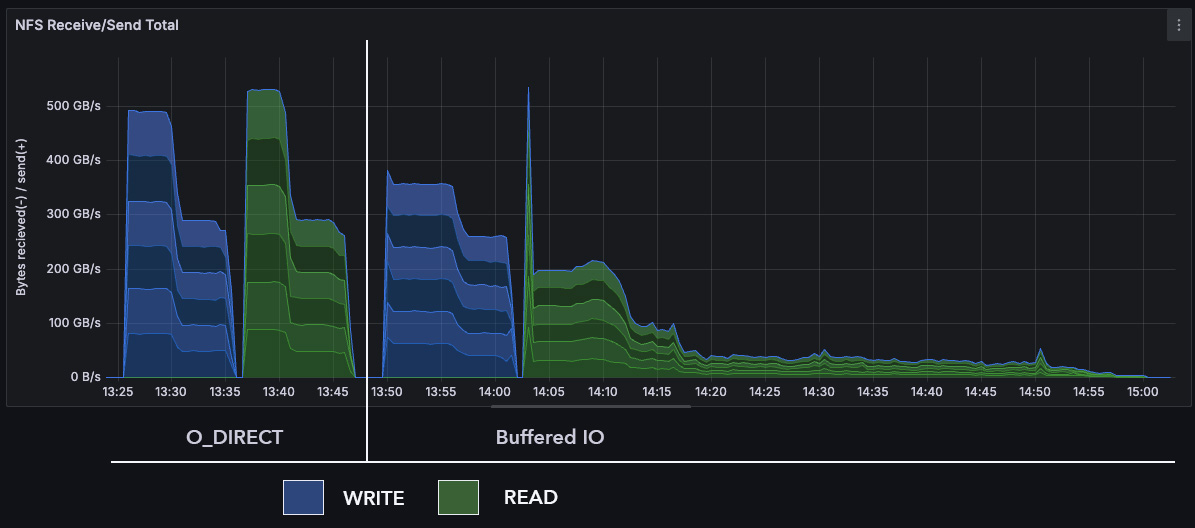
On Wed, 2025-06-11 at 08:23 -0400, Mike Snitzer wrote: > On Wed, Jun 11, 2025 at 12:00:02AM -0700, Christoph Hellwig wrote: > > On Tue, Jun 10, 2025 at 04:57:36PM -0400, Mike Snitzer wrote: > > > IO must be aligned, otherwise it falls back to using buffered IO. > > > > > > RWF_DONTCACHE is _not_ currently used for misaligned IO (even when > > > nfsd/enable-dontcache=1) because it works against us (due to RMW > > > needing to read without benefit of cache), whereas buffered IO enables > > > misaligned IO to be more performant. > > > > This seems to "randomly" mix direct I/O and buffered I/O on a file. > > It isn't random, if the IO is DIO-aligned it uses direct I/O. > > > That's basically asking for data corruption due to invalidation races. > > I've seen you speak of said dragons in other threads and even commit > headers, etc. Could be they are lurking, but I took the approach of > "implement it [this patchset] and see what breaks". It hasn't broken > yet, despite my having thrown a large battery of testing at it (which > includes all of Hammerspace's automated sanities testing that uses > many testsuites, e.g. xfstests, mdtest, etc, etc). > I'm concerned here too. Invalidation races can mean silent data corruption. We'll need to ensure that this is safe. Incidentally, is there a good testcase for this? Something that does buffered and direct I/O from different tasks and looks for inconsistencies? > But the IOR "hard" workload, which checks for corruption and uses > 47008 blocksize to force excessive RMW, hasn't yet been ran with my > "[PATCH 6/6] NFSD: issue READs using O_DIRECT even if IO is > misaligned" [0]. That IOR "hard" testing will likely happen today. > > > But maybe also explain what this is trying to address to start with? > > Ha, I suspect you saw my too-many-words 0th patch header [1] and > ignored it? Solid feedback, I need to be more succinct and I'm > probably too close to this work to see the gaps in introduction and > justification but will refine, starting now: > > Overview: NFSD currently only uses buffered IO and it routinely falls > over due to the problems RWF_DONTCACHE was developed to workaround. > But RWF_DONTCACHE also uses buffered IO and page cache and also > suffers from inefficiencies that direct IO doesn't. Buffered IO's cpu > and memory consumption is particularly unwanted for resource > constrained systems. > > Maybe some pictures are worth 1000+ words. > > Here is a flamegraph showing buffered IO causing reclaim to bring the > system to a halt (when workload's working set far exceeds available > memory): https://original.art/buffered_read.svg > > Here is flamegraph for the same type of workload but using DONTCACHE > instead of normal buffered IO: https://original.art/dontcache_read.svg > > Dave Chinner provided his analysis of why DONTCACHE was struggling > [2]. And I gave further context to others and forecast that I'd be > working on implementing NFSD support for using O_DIRECT [3]. Then I > discussed how to approach the implementation with Chuck, Jeff and > others at the recent NFS Bakeathon. This series implements my take on > what was discussed. > > This graph shows O_DIRECT vs buffered IO for the IOR "easy" workload > ("easy" because it uses aligned 1 MiB IOs rather than 47008 bytes like > IOR "hard"): https://original.art/NFSD_direct_vs_buffered_IO.jpg > > Buffered IO is generally worse across the board. DONTCACHE provides > welcome reclaim storm relief without the alignment requirements of > O_DIRECT but there really is no substitute for O_DIRECT if we're able > to use it. My patchset shows NFSD can and that it is much more > deterministic and less resource hungry. > > Direct I/O is definitely the direction we need to go, with DONTCACHE > fallback for misaligned write IO (once it is able to delay its > dropbehind to work better with misaligned IO). > > Mike > > [0]: https://lore.kernel.org/linux-nfs/20250610205737.63343-7-snitzer@xxxxxxxxxx/ > [1]: https://lore.kernel.org/linux-nfs/20250610205737.63343-1-snitzer@xxxxxxxxxx/ > [2]: https://lore.kernel.org/linux-nfs/aBrKbOoj4dgUvz8f@xxxxxxxxxxxxxxxxxxx/ > [3]: https://lore.kernel.org/linux-nfs/aBvVltbDKdHXMtLL@xxxxxxxxxx/ To summarize: the basic problem is that the pagecache is pretty useless for satisfying READs from nfsd. Most NFS workloads don't involve I/O to the same files from multiple clients. The client ends up having most of the data in its cache already and only very rarely do we need to revisit the data on the server. At the same time, it's really easy to overwhelm the storage with pagecache writeback with modern memory sizes. Having nfsd bypass the pagecache altogether is potentially a huge performance win, if it can be made to work safely. -- Jeff Layton <jlayton@xxxxxxxxxx>
{kind=link}
{kind=link}
{kind=link}
